プロジェクト
取り組んでいる主な研究プロジェクト
NoCha
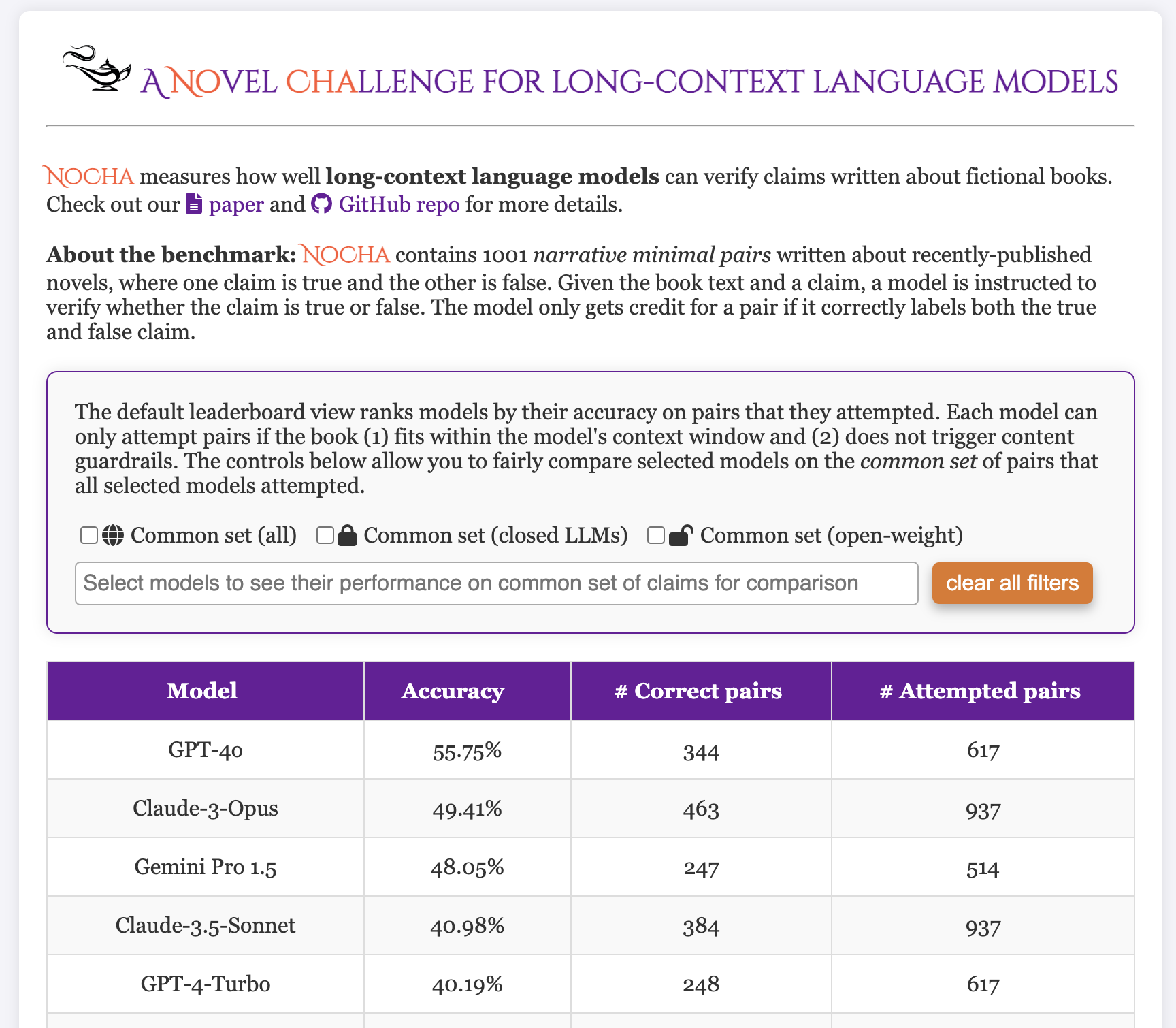
大規模言語モデルは、扱えるトークン数を 2k から 2M にまで拡大するなど目覚ましい進歩を遂げています。しかし、これらをどう評価するかは依然として大きな課題です。書籍長の入力を扱いつつ訓練データへの汚染を避けるのは容易ではありません。NoCha では、楽しみのために最近刊行された小説を読んだ読者にご協力いただき、この問題に取り組んでいます。読者は、読んだ本に関する真偽のペアからなる文を作成します。同じ出来事や登場人物について、含まれる虚偽の情報のみが異なる二文を書いてもらうのです。モデルは本文を文脈として与えられたうえで、これらの主張を判定します。発想は単純で、もし「Despite her skills as an Apoth, Nusis is unable to reverse engineer the type of portal opened by the reagents key found in Rona's wooden chest.」が真であると分かれば、「By using her skills as an Apoth, Nusis is able to reverse engineer the type of portal opened by the reagents key found in Rona's wooden chest.」が偽だと分かるはずです。とはいえ、現行モデルにとってこのタスクは難しく、結果は NoCha リーダーボード でご覧いただけます。
LitMT
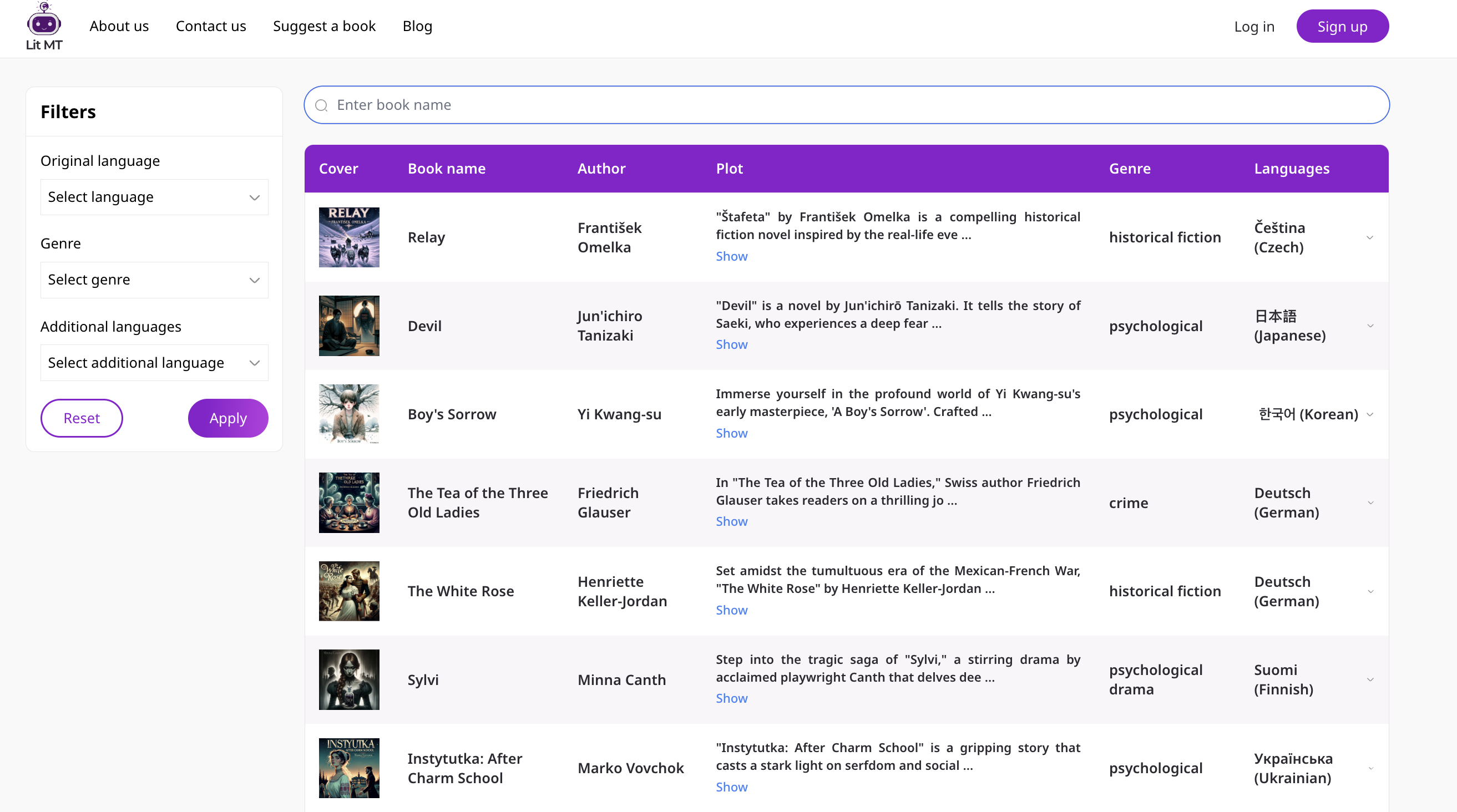
LitMT では、機械翻訳が翻訳者の仕事をどのように支援し、新しい物語を読者に届けられるかを探っています。機械翻訳は翻訳者の認知的負荷を軽減することで作業を助けます(O'Brien, 2012)。一方で、もう一つの側面が「読者」です。私たちは機械翻訳された世界文学を共有する ウェブサイト を構築し、これまで他言語で読めなかった作品も含めて公開しています。本プロジェクトは翻訳プロセスそのものと同様に、読者がそうした翻訳をどう感じるかを理解することをも目的としています。読者から直接フィードバックを集めることで、機械翻訳をより良く、より読みやすいものにしていきたいと考えています。読者の声から「うまくいっていること/いないこと」を学び、母語に関わらず誰もが文学にアクセスできる世界を目指す、刺激的な領域だと思っています。

HCI-MT
本プロジェクトでは、NLP システムが翻訳者の作業をいかに効率化し品質を高められるかを研究しています。これらのツールには大きな可能性がありますが、翻訳者の日々のワークフローへどう組み込むかは自明ではありません。私たちは文学翻訳者と協力し、彼ら/彼女らによる技術活用の実態を調査しています。目的は、高品質な翻訳をより効率的に生み出すために、これらのシステムをどう最も効果的に活かせるかを明らかにすることです。